
Q-learning (also referred as Q Star Q*) represents a pivotal leap in the field of AI, particularly in the quest for Artificial General Intelligence (AGI). At its core, Q-learning is about enabling AI to make decisions with minimal human intervention. By employing a system where an AI ‘agent’ iteratively improves its decision-making through trial and error, Q-learning nudges AI towards a more generalized understanding of tasks, rather than just specialized proficiency.
The pathway to AGI via Q-learning could be realized through the algorithm’s capacity to learn from diverse and complex environments, acquiring and applying knowledge across a broad range of tasks. By integrating Q-learning with other AI disciplines like deep learning and transfer learning, it may be possible to create systems that not only excel at specific tasks but also understand and perform a vast array of activities with human-like adaptability.
The real challenge for Q-learning in the context of AGI is how to scale this learning process to handle the complexity of the real world, which includes mastering language, abstract thinking, and creative problem-solving. AGI demands an AI that can navigate a multitude of scenarios, assimilate information from various domains, and apply this knowledge flexibly across different contexts.
With Q-learning, the AI community sees potential in developing an AI agent that can discern patterns and make decisions that generalize across different fields. This involves creating more advanced algorithms that can process more nuanced reward signals and learn from a wider array of experiences, much like how a human learns from a young age. If successful, Q-learning could be a cornerstone in building AI that matches human cognitive abilities, leading to the eventual realization of AGI.
Surpassing human intelligence hinges on transitioning from merely replicating learned data outputs (training by imitation) to enabling a model to autonomously enhance its capabilities. Neural networks must evolve to independently interpret the environment by analyzing outcomes, such as wins, losses, or scores, to refine their understanding and decision-making processes. (source: Mastering the game of Go without human knowledge | Nature)
What is Q-learning in Artificial Intelligence?
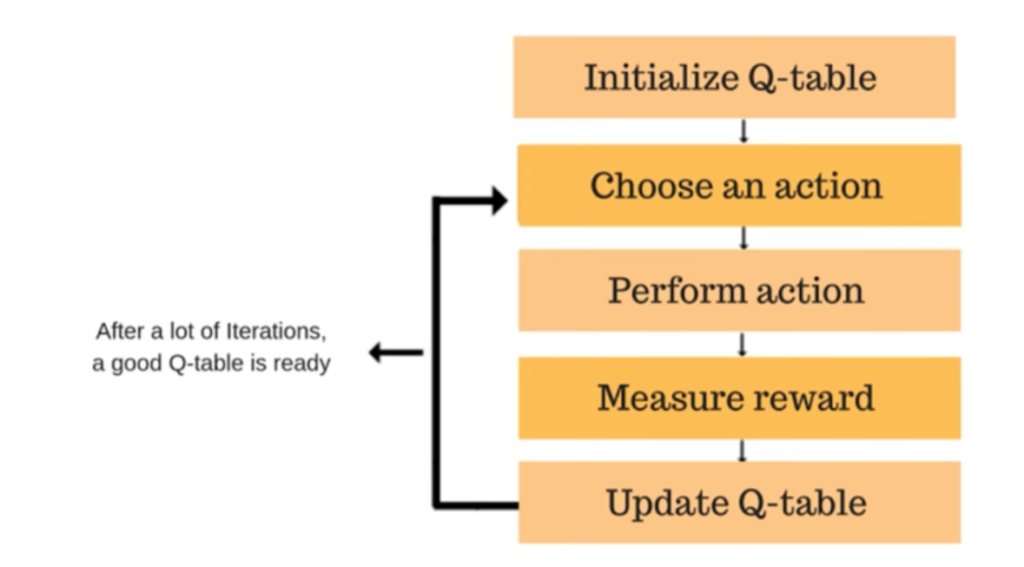
Q-learning in AI refers to a model-free reinforcement learning technique, where an AI ‘agent’ interacts with a dynamic environment to perform certain actions. It gets feedback in the form of rewards or penalties, which guide the agent to optimize its actions to achieve the highest cumulative reward. Unlike direct instruction, Q-learning enables the AI to discover an optimal action-selection policy through trial and error, learning from experiences without a predetermined path.
Does Deep Q-learning fall under AI?
Indeed, Deep Q-learning is an AI technology that enhances Q-learning by incorporating deep neural networks. This approach enables the handling of high-dimensional sensory inputs, making it suitable for tackling complex problems like mastering board games, autonomous driving, or advanced robotics. Deep Q-learning can interpret vast amounts of unstructured data to make accurate predictions about the best actions to take.
Can you explain OpenAI’s Q Algorithm?
OpenAI has developed a variant of Q-learning, often referred to as the Q Algorithm, that pushes the boundaries towards more sophisticated and generalized decision-making capabilities. It’s designed to handle a broader range of environments with an off-policy method, which allows the AI to learn from actions that are outside its current policy. This feature is crucial for developing more flexible and adaptable AI systems capable of learning from a wide variety of scenarios, even those it hasn’t directly experienced.
Is reinforcement learning used in ChatGPT?
ChatGPT integrates reinforcement learning (RL) principles within its architecture. While it’s fundamentally built on a transformer-based model, which is a deep learning algorithm, ChatGPT applies RL to fine-tune its outputs. By receiving and incorporating user feedback, much like rewards in an RL framework, ChatGPT continually refines and enhances its language generation capabilities, aiming to produce more accurate, relevant, and context-aware responses.
What are some real-world applications of Q-learning?
Real-world applications of Q-learning span various industries and fields. In gaming, Q-learning helps in developing non-player characters (NPCs) that can adapt to players’ strategies. In finance, it aids in creating trading algorithms that optimize investment strategies over time. In robotics, Q-learning algorithms enable robots to learn and perform tasks autonomously. In healthcare, it’s applied in personalized medicine, where AI learns to tailor treatments to individual patients’ needs. Additionally, Q-learning is used in logistics to optimize routes and schedules for delivery networks.
NB: As an FYI I used openAI gpt4 to help me generate this article and image

